
[Update 2022 Oct. 30] Added the text-to-video models recently introduced: Imagen Video and Phenaki.
Notation
| Symbol | Meaning |
|---|---|
| $g_\theta$ | Generator network with parameters $\theta$ |
| $\mathbf{c}$ | A caption, represented as a sequence of tokens |
| $x$ | An input image, optionally fed to $g_\theta$ to perform modification on it |
| $y$ | The output image, sampled from $g_\theta(\mathbf{c})$ or $g_\theta(\mathbf{c}, x)$ |
| $\mathbf{z}$ | A latent vector |
| $\mathbf{h}$ | Hidden states, intermediate representation of the input data |
Intro and problem formulation
We refer to text-to-image generation as the tasks of generating visual content conditioned on some text description. The simplest is the one of generating an image $y \sim g_\theta(\mathbf{c})$ from a caption $\mathbf{c}$, but this also contains tasks of infilling / inpainting or variation for which a model takes both a caption and an image as input.
There is a huge amount of works on both vision and text models, independently. We will omit most details and assume you are familiar with diffusion models and transformers, and focus more specifically on the link between those two modalities (one discrete one continuous). As of the horizon of 2021, deep learning generative models were already capable to generate realistic content of high quality. DeepDream or StyleGan are known examples towards this attempt. These models were however hard to control and often limited in term of diversity, so that they were not used in mainstream application. Despite their remarkable capabilities, they lack of fine-grained control to be widely used by the general public. We then began to see researchers putting a lot of effort to create a stronger bridge between the text and image modalities, seeking for this control, hoping to generate content with high details.
For reads on diffusion models and transformers, I recommend you respectively these blog post from Lilian Weng and Jay Alammar.
alignDRAW
alignDRAW is one of the first work on image generation from caption. It was introduced in Generating images from captions with attention and is one of the first attempt to text-to-image generation.
It is an extension of the DRAW network, to which text captions are included in each generation step and the training objective is adapted consequently. DRAW is a model for image generation which work by iteratively refining the generated image. It is built as a “sequential” variational auto-encoder: an encoder (named inference network) determines a latent distribution representing the features of an input image; a decoder (named generative network) generating images conditioned on the latent distribution. Both networks are sequential (LSTM) using attention, and the decoder’s output are successively refined to generate the final image after $T$ steps, instead of creating it in a single step. The attention is used in the read and write operations to restrict the area observed by the encoder and modified by the decoder.
Schema of the alignDRAW model training and inference. Figure taken from the original paper.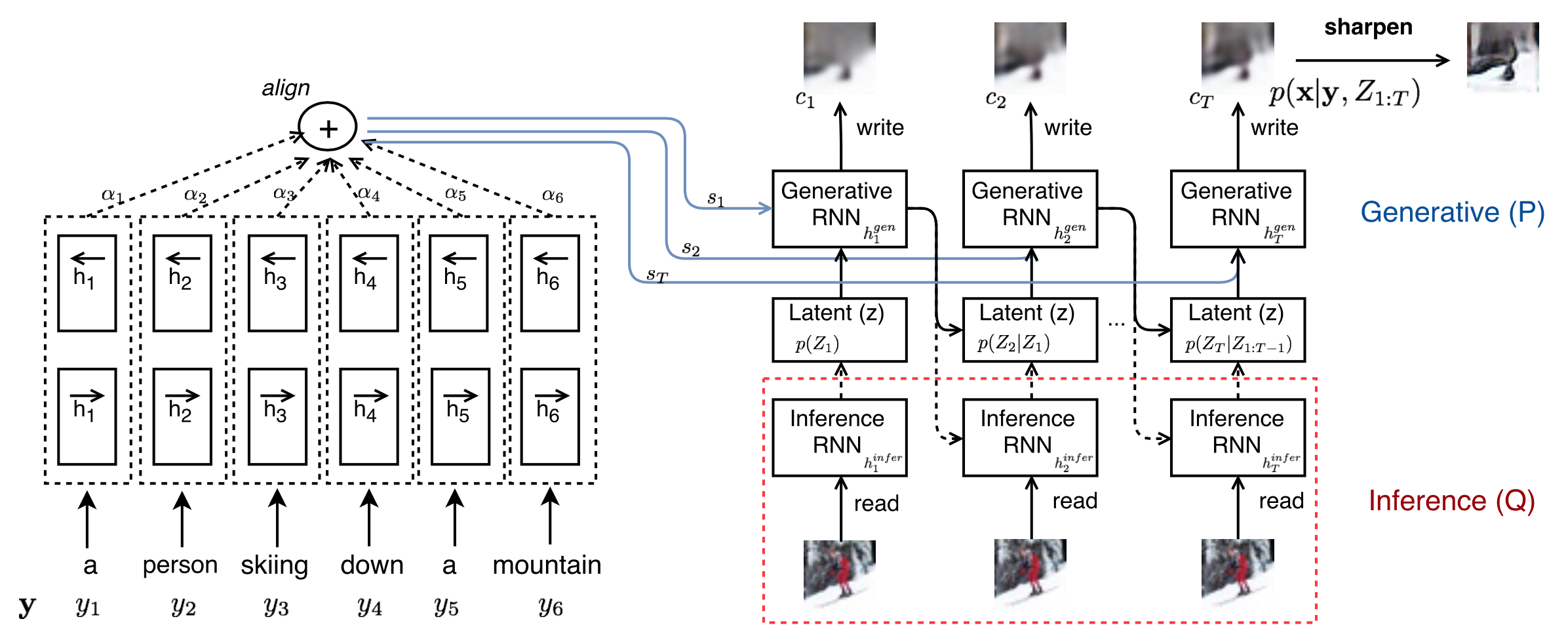
At each time step $t$, the encoder receives input from the image $x$ and the previous hidden state $\mathbf{h}_{t-1}^{dec}$ from the decoder, and outputs a latent distribution $Q(\mathbf{z}_t \lvert x, \mathbf{h}_{t}^{enc}) \propto Q(\mathbf{z}_t \lvert x, \mathbf{z}_{t-1})$. At each time step, a sample $z \sim Q(\mathbf{z}_t \lvert x, \mathbf{h}_{t}^{enc})$ is drawn from the latent distribution and passed to the decoder, which computes $\mathbf{h}_t^{dec}$. This last hidden state is added to the canvas matrix $\mathbf{C}_t$ via the write operation, which is ultimately used to reconstruct the image: $\mathbf{C}_t = \mathbf{C}_{t-1} + \mathrm{write}(\mathbf{h}_t^{dec})$.
alignDRAW adds to this framework a caption $\mathbf{y}$, as a sequence of token. $\mathbf{y}$ is processed by a bi-directional LSTM network which returns hidden states $\mathbf{h}^{lang}$, from which attention is performed with the hidden states from the decoder $\mathbf{h}^{dec}_{t-1}$ in order to get as output caption representation $\mathbf{s}_t$. $\mathbf{s}_t$ are fed to the decoder as hidden states.
The DRAW model is known to generate blur results. The authors of alignDRAW then added a post-processing step to sharpen the images thanks to a trained adversarial network.
Images generated with alignDRAW with their input captions. Figure taken from the original paper.
Trained on the COCO dataset, the model one of the first being able to generate images conditioned on human captions. Due to the limitations at this moment (2016), the results are however in low resolution, mostly blur and often very similar (i.e. with few diversity, the COCO dataset being relatively restricted). Big progresses on this task are and will soon improve the results.
GAN with text conditioning
In the following months, Reed et al. proposed another way to condition image generation on text within a GAN framework. The caption is first encoded through a fully-connected layer into an embedding which is then concatenated to the noise input to be fed to the generator. During training, the discriminator also receives the caption embedding in order to discriminate wrong image / caption pairs.
Schema of the proposed GAN with text conditioning. Figure from Reed et al.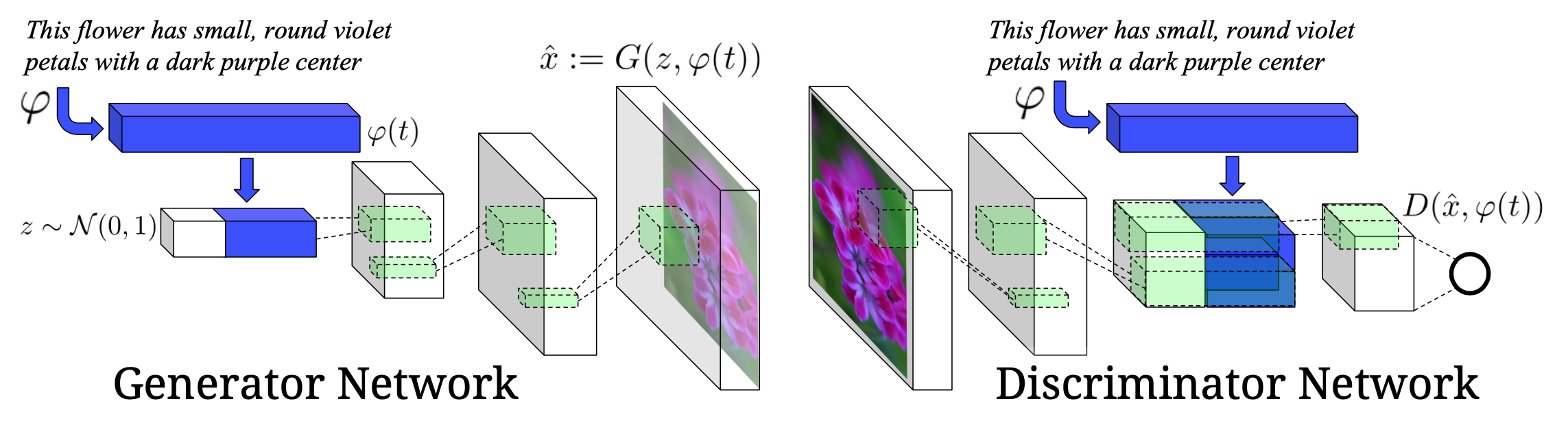
This simple yet effective solution allows to generate images, and were proved to work well on simple datasets such as the Caltech-UCSD Birds and Oxford-102 Flowers datasets.
AttnGAN also uses this principle and extends it by adding a contrastive loss term to the training objective.
The captions are encoded into both a sequence of embeddings and a single sentence feature vector $\mathbf{s}$. The later is concatenated to the noise input of the generator as previously. In AttnGAN however, there are several generators forming a chain of image upscaling. They produce an image of a certain resolution, from the image produced by the previous generator in the chain and the text embeddings (except the first which takes random noise + $\mathbf{s}$ in input). Each generator is associated to a discriminator, which binary classes the result as real or fake and updates the parameter of the generator. Hence the overall model is trained in disjoint parts which focuses on different aspects of the generation conditioned on the text caption while upscaling the image.
Schema of the attnGAN architecture. Figure from the original paper.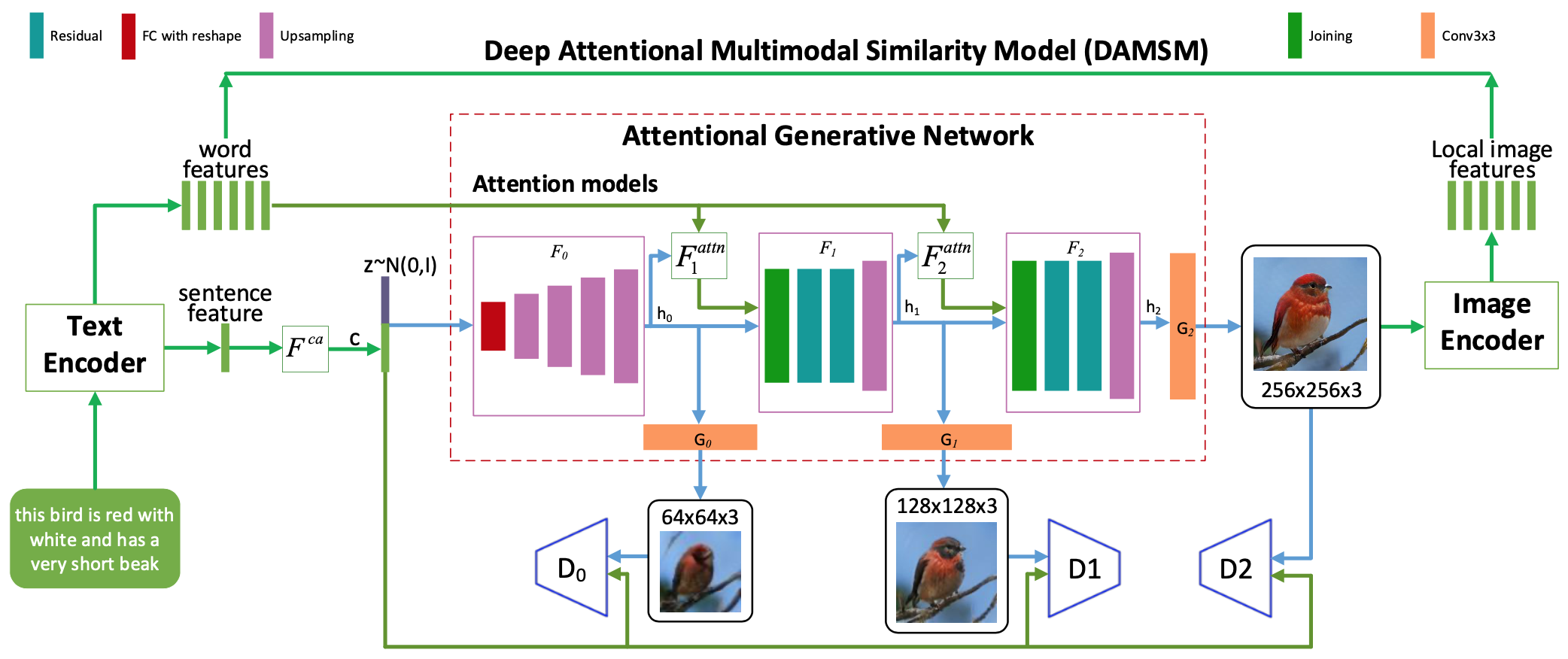
The last part of the training is the Deep Attentional Multimodal Similarity Model (DAMSM). It is a contrastive learning approach which measures the similarity of image-text pairs and turns it into a loss value, in order to update the model’s parameters. In practice, the produced image is passed through an image-encoder network which returns a fixed feature vector, on which attention is applied with the text embeddings.
Image input captions generated from AttnGAN. Figure from the original paper.
Results on the COCO and CUB datasets showed very plausible and improved results compared to what has been achieved yet. It is, AFAIK, the first text-to-image architecture using contrastive learning to train the generator model. We will see that contrastive learning will become a key ingredient of the future text-to-image generative models.
Multi-modal Transformers
Dall-E (v1)
In June 2021, OpenAI released Dall-E (the first version at this time), a new text-to-image model based on a transformer, which models the text and image data as a single stream of data.
The model receives both modalities as a sequence of up to 1280 tokens, and is trained with teacher forcing and maximum likelihood estimation. During inference, it generates image tokens autoregressively.
In order to process images, input images are passed to a discrete variational auto-encoder (VAE) which downsizes them from a 256 * 256 RGB resolution to a grid of 32 * 32 values (tokens), with 8192 possible values (vocab size). Note that the images tokens must be somehow sampled. As the sampling is not deterministic thus not differentiable, the gumbel-softmax relaxation is used here during training, and argmax during inference. Then, a caption of up to 256 BPE-encoded text tokens is concatenated to the image tokens, forming a sequence of 1280 discrete elements, passed to a transformer. Image tokens can attend to all text tokens, while text tokens can only attend to previous text tokens (causal attention mask), and a row, column, or convolutional attention mask is used for image tokens between them. The transformer is trained to model the joint distribution over the text and image tokens.
Given the progresses of the processing units, Dall-E achieved to perform very good and plausible results, beating the state of the art models at the time. Samples generated with Dall-E were preferred by humans 90% of the time according to the authors.
We see that here too, the text is used in combination with a prior distribution in order to steer the generation towards an expected result. This process will not last long and rapidly be replaced.
CogView (v1 & v2)
A few months later, CogView was released. It is based on the same idea of processing both modalities as a single data stream and autoregressively predict the image. The image encoder of CogView is however based on the VQ-VAE network.
It is able to generate images of better quality than Dall-E according to the authors, with smaller FID, but at the cost of blurriness.
In CogView 2, regions of the image tokens are masked during the training and adding iterative super-resolution steps to the generation process. The image quality is further improved and the model more faithful in its prediction.
CLIP
We now have to make a stop and learn about to CLIP. CLIP is a model introduced by OpenAI pre-trained to learn visual representations from text captions, to perform downstream tasks such as OCR, geo-localization or action recognition.
It is trained with a contrastive learning objective: given a batch of $N$ image-caption pairs, is learns to predict the correct pairing among the $N \times N$ possible. The batch of image is passed to an image encoder, a ResNet with several modifications here, which returns features: $E_i: \mathbb{R}^{N \times h \times w \times c} \rightarrow \mathbb{R}^{N \times d_i}$. Each caption is bounded with special [SOS] and [EOS] tokens, the batch is passed to a text encoder, a Transformer, which returns features for each of them at the index of the [EOS] token index, $T: \mathbb{R}^{N \times L} \rightarrow \mathbb{R}^{N \times d_t}$.
CLIP’s training and inference process. Figure from the original paper.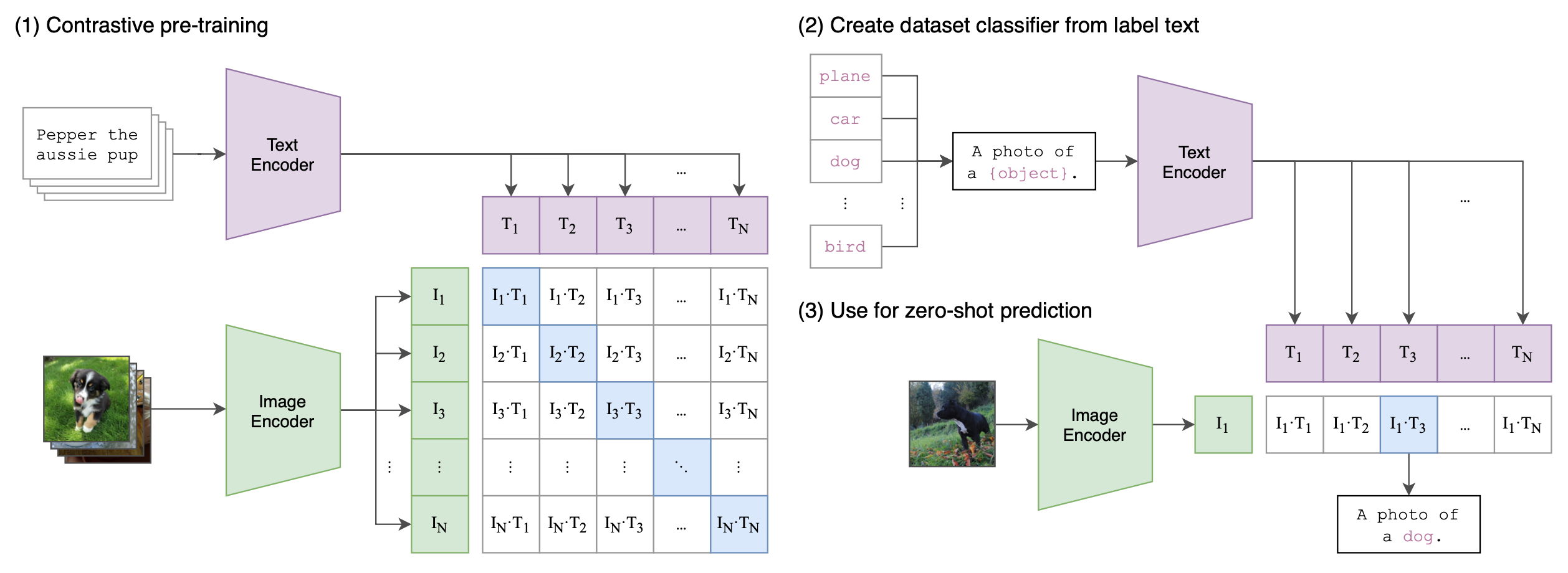
Each encoder’s representation is then projected linearly to a multi-modal embedding space. The training loss is defined as the cross-entropy on the cosine similarity of each image-caption pair. The training procedure can be summarized as (numpy-like pseudocode taken from the figure 3 of the original paper):
# image_encoder - ResNet or Vision Transformer
# text_encoder - CBOW or Text Transformer
# I[n, h, w, c] - minibatch of aligned images
# T[n, l] - minibatch of aligned texts
# W_i[d_i, d_e] - learned proj of image to embed
# W_t[d_t, d_e] - learned proj of text to embed
# t - learned temperature parameter
# extract feature representations of each modality
I_f = image_encoder(I) #[n, d_i]
T_f = text_encoder(T) #[n, d_t]
# joint multimodal embedding [n, d_e]
I_e = l2_normalize(np.dot(I_f, W_i), axis=1)
T_e = l2_normalize(np.dot(T_f, W_t), axis=1)
# scaled pairwise cosine similarities [n, n]
logits = np.dot(I_e, T_e.T) * np.exp(t)
# symmetric loss function
labels = np.arange(n)
loss_i = cross_entropy_loss(logits, labels, axis=0)
loss_t = cross_entropy_loss(logits, labels, axis=1)
loss = (loss_i + loss_t)/2
The authors trained it on 400M pairs collected from the internet, and found it extremely effective on zero-shot tasks, with competitive results compared to task-specific models. It actually learns to perform a wide set of tasks during this pre-training only.
Its other strength is its flexibility. For all subsequent tasks, CLIP is not restricted to fixed set of classes, but can leverage the flexibility of language modeling. The only limit is the vocabulary size, and the input sizes.
As it performs very well to measure the similarity of an image and a caption, it can thus be used as a metric. End even more, as a criterion when combined with other models.
GAN + CLIP guidance
CLIP was actually very quickly put in use for image generation, with the BigSleep and VQ-GAN + CLIP notebooks. The idea is to use CLIP to steer a generative model towards an image that matches a caption.
The authors of these works used the BigGAN and the VQ-GAN models, we could in fact use any generative model as long as it takes latent input and all the operations between it and the generated image are differentiable.
How CLIP is used to steer a generative model to create an image matching a caption. CLIP is used as a criterion, gradients are backpropagated back to the latent distribution. The process is repeated until the similarity reaches a satisfying value.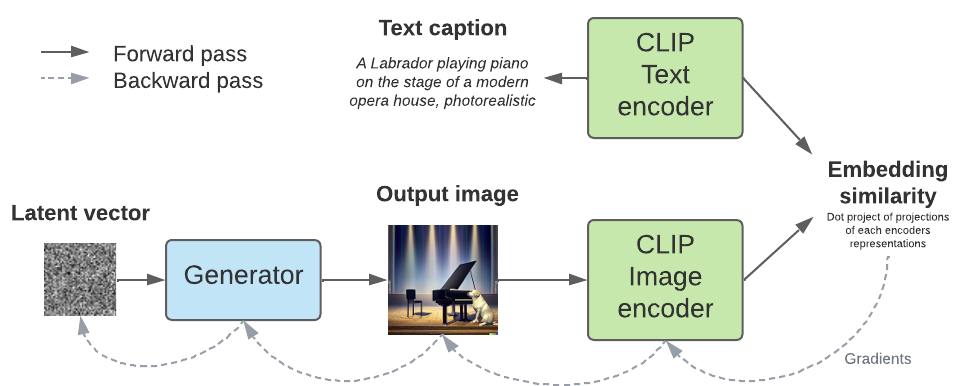
Here CLIP is used as a criterion. It measures the similarity between the generated image and the target caption, and use this value as a loss to backpropagate gradients back to the input latent of the generator. The next iteration should provide an image with a higher similarity. This step is repeated several times until the similarity reaches a satisfying value.
This framework is very convenient for text-to-image generation, and is up to this day used by the state-of-the-art models. It first automatically converged towards good and expected images, while giving control and metrics over the similarity of these results. CLIP is “generator-agnostic” as long as it takes latent and is fully differentiable. And it leverages and benefits from the very effective contrastive learning of CLIP, which know accurate and faithful image representations, being a strong steering for the generation task.
StyleCLIP also stands on CLIP guidance.
GLIDE and classifier-free guidance
In march 22, OpenAI reveled GLIDE, standing for Guided Language to Image Diffusion for Generation and Editing. It is similar to previous models, but uses a diffusion generator. The authors experimented with both CLIP and classifier-free guidance, and found that the latter is preferred by human for both photorealism and caption similarity.
Classifier-free guidance works by training a single diffusion model on both a conditional $p_\theta(\mathbf{z} \lvert \mathbf{c})$ and an unconditional $p_\theta(\mathbf{z})$ objectives. The conditional is parameterized through a score estimator $\epsilon_\theta(\mathbf{z}_\lambda, \mathbf{c})$, the unconditional by $\epsilon_\theta(\mathbf{z}_\lambda)$. We perform a linear combination of both scores, $(1+w) \epsilon_\theta (\mathbf{z}_\lambda, \mathbf{c}) - w \epsilon_\theta (\mathbf{z}_\lambda)$, where $w$ controls the classifier guidance, to get the direction to draw gradients.
This technique does not require a separate classifier model, and present the advantage of relying on the model’s knowledge, thus assuring its robustness. It has since been used and preferred in future diffusion works.
Dall-E 2
A month later, OpenAI (again) released and deployed what will become one of their most known models: Dall-E 2.
Dall-E 2 is also based on CLIP and diffusion models, but does not use the former to guide the latter. Instead, a caption is converted to a CLIP embedding, which is passed to a prior (auto-regressive or diffusion) which converts it to an image embedding, which is in turn used to condition a diffusion decoder to produces the final image. They called this process “unCLIP”.
During the training of the prior and diffusion decoder, the parameters of CLIP are frozen (and only the text encoder is used). These stacked components form a generative model $p_\theta(y, \mathbf{c})$ which generate an image conditioned on a text caption, without guidance.
Schema of the training procedure of Dall-E 2. Figure taken from the original paper.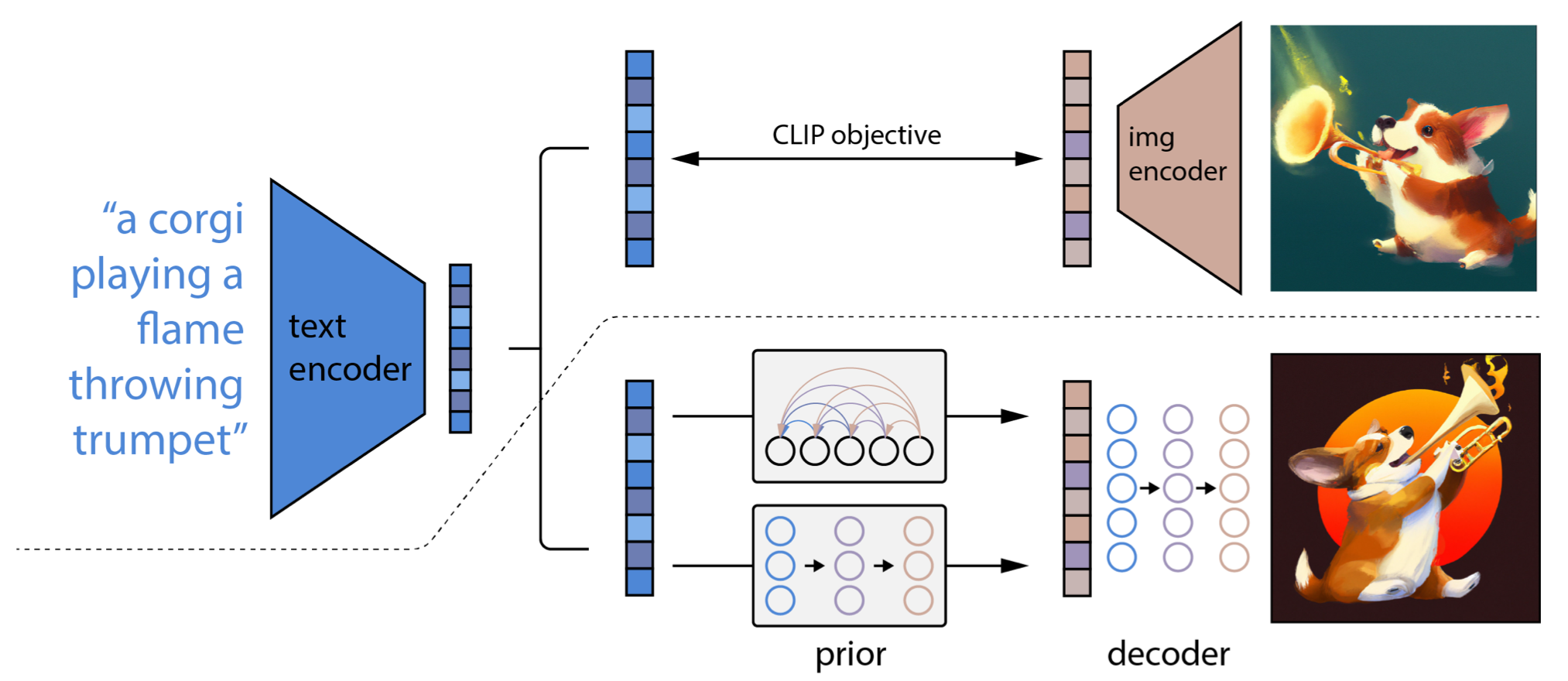
Note that it would be possible to directly condition the decoder on the caption, or the CLIP text embeddings, with no prior. However the author observed that the prior improves the quality of the results. They tested with both an autoregressive and a diffusion prior. The latter performed best in every human evaluation metrics.
OpenAI deployed shortly after an online demo of Dall-E 2, based on a 3.5B parameters, and giving access to selected people. ATOW, the access is still given through a waitlist. The demo initially generated 6 images at each iteration, and the number of iteration were not limited. Recently they set a credit system to limit the iterations and monetize the service.
Craiyon (originally Dall-E Mini, renamed after OpenAI expressed their opposition) is a free, open-source and accessible version of Dall-E 2. The base model is not however smaller than the one deployed by OpenAI.
In the next week after the release of Dall-E 2, Google released its own text-to-image and competitor model.
Imagen
Imagen is Google’s response to Dall-E 2. The team behind was actually working on the project before Dall-E was released.
Imagen is also based on a diffusion model, trained with classifier-free guidance to iteratively generate 64x64 px images. These images are then fed to two cascaded text-conditional super-resolution diffusion models, which upsample the images to 256x256 px then 1024x1024 px.
The text encoder can actually be any large language model such as BERT or T5, which is frozen during Imagen’s training. The authors experimented with T5-XXL and CLIP, founding that people preferred results produced with T5-XXL.
The base 64x64px model is a U-Net with text conditioning adapted from DDPM. Text embedding vectors are added to the diffusion timesteps embeddings.
Super-resolution models are also U-Nets adapted from DDPM with improvements to reduce the memory usage and inference time. Cross-attention is applied to condition on text for both networks. The authors claim that “making the super-resolution models aware of the amount of noise added, via noise level conditioning, significantly improves the sample quality and helps improving the robustness of the super-resolution models to handle artifacts generated by lower resolution models”.
The authors also introduced a new method called Dynamic thresholding, which during each sampling step clips the pixels values to a $[-s, s]$ interval where $s$ is a percentile of pixel value. This has the benefit to counterbalance the lack of image fidelity that can emerge from guidance-free diffusion when the guidance weight is high. It reduces the values of saturated pixels and prevent saturation at each step.
Throughout this work, the authors notably noticed that:
- Scaling the text encoder is very effective, more than scale the diffusion models, resulting in results of better quality and image-text alignment.
- Dynamic thresholding result in images with higher fidelity than static thresholding or none.
- Noise conditioning augmentation in super-resolution networks yields results with higher FID and CLIP scores.
- Cross-attention text conditioning yields better results than a simple mean or attention pooling operations, resulting in higher image-text alignment.
Parti
In the following weeks again, another team of google released once again a new text-to_image model they called Parti (Pathways Autoregressive Text-to-Image).
Parti is actually a Transformer based model, which contrasts with other model in that it is autoregressive. It is a seq2seq architecture, where the encoder takes the input caption and the decoder generates the image. The images are discretized through a ViT-VQGAN which acts as a tokenizer and detokenizer, over a vocabulary of 8192 tokens.
Schema of Parti’s architecture. Figure taken from the original paper.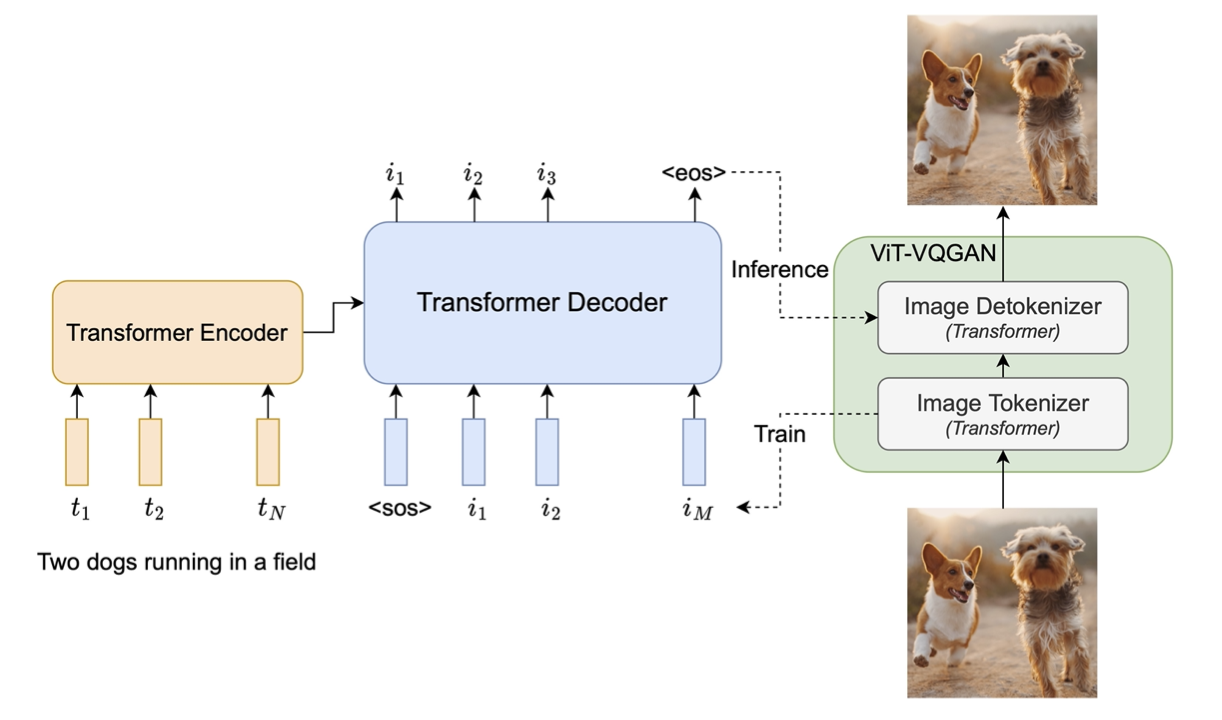
Parti works with 256x256px images, which are downsampled and upsampled during training and inference.
There is not much to say on the technical stack of Parti. The major contribution of this work is probably how the authors showed that scaling is a crucial factor in order to get realistic and well text-image aligned results.
Results generated from Parti. We clearly see the difference in both quality and text-image alignment between the small and big versions of Parti. Figure taken from the original paper.
Latent diffusion models and Stable Diffusion
As we have seen so far, diffusion models are the backbones of most text-to-image systems. Their iterative refinement generative process makes them particularly well suited to create both realistic and controllable content.
We did not mention however yet that the inference time of diffusion models is high, more than most neural neural networks in average. This is partly due to the need to store and backpropagate the gradients, of models, for a large number of steps, of models often very large.
Researchers from the Ludwig Maximilian University of Munich then introduced the “Latent Diffusion Model”. The core idea is to perform the diffusion step to a latent space level, instead of the pixel level as currently done. This is motivated by the fact that the latent space can contain most of the semantic and important information about an image and the associated caption, while the overall pixel level also contains the perceptual details that are not necessarily required.
The compression step is done by an Autoencoder, whose the encoder compresses the images $\mathbf{x} \in \mathbb{R}^{H \times W \times 3}$ into latent representation $\mathbf{z} \in \mathbb{R}^{h \times w \times c}$. Images are downsampled by a factor $f = H/h = W/w = 2^m,: m \in \mathbb{N}$. The decoder reconstructs the images from the latent.
Schema of the architecture of the latent diffusion model. Image taken from the original paper.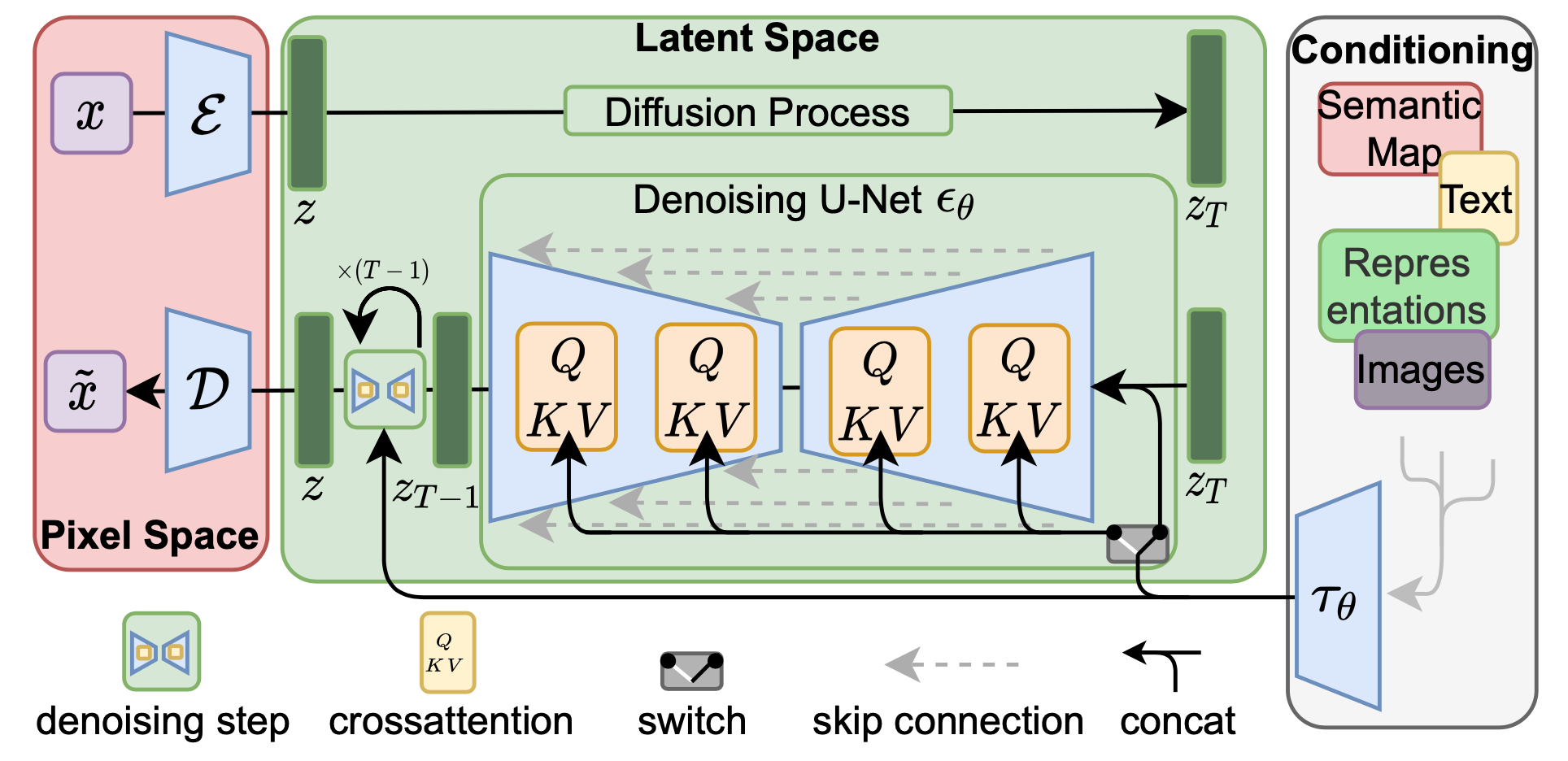
Conditioning, based on text, image or semantic map can be performed by cross-attention within the U-Net denoising modules, as shown on the figure above.
Performing the denoising steps in the latent space significantly reduces the training cost, and speed up the inference, while keeping results of similar quality.
Later in summer 2022, the authors paired with stability.ai, to build the first big open text-to-image model, commonly called Stable Diffusion. Stability shared their compute capabilities to train a big version of the latent diffusion model which processes images of 512*512px. The UNet have 860M parameters, and the text encoder 123M. It can run on GPU with 10GB of VRAM. The parameters are openly shared and can be downloaded from the Hugging Face space. An online demo is also available.
Images generated with StableDiffusion from the caption ‘A Labrador playing piano on the stage of a modern opera house, photorealistic’.
The figure above shows what Stable Diffusion can generates from a caption of dog musician. All backgrounds are very accurate and realistic, but the foregrounds are not very coherent.
The release of Stable Diffusion made a big noise in the machine learning community. At the moment where big companies, among the few ones with big enough computational capabilities, introduced their text-to-image models and made them available only through monetized systems, Stable Diffusion broke this dynamic. Now anyone can generate images on consumer-class GPUs.
Midjourney
Midjourney is a company that develop its own text-to-image model. It is currently (sept. 2022) in open beta that you can join. The interface works through an API linked to their Discord server, on which you can interact to generate images. It is based on a freemium business model, with 25 free generation after registration and \$10 and \$30 monthly subscriptions.
After its first deployment it rapidly spread across the internet and saw a massive usage. As of august 2022, David Holz (founder) reported that the company was already profitable.
Unified-IO
Unified-IO is kind of universal architecture, aiming to solve a wide variety of tasks, among which “pose estimation, object detection, depth estimation and image generation, region captioning, referring expression comprehension, question answering and paraphrasing”.
But creating a single model handling several modalities and tasks poses serious challenges. The commonly used method to address this is to put several output heads, one per modalities and/or task, on top of a common backbone model. This approach however requires to manually design these heads, by freeze the backbone and finetuning each of them individually. This limits the capacity of the backbone to transfer from a task to another. Moreover, the backbone has to be carefully pre-trained so the latents work well for each head.
Schema of the architecture of Unified-IO. Figure taken from the original paper.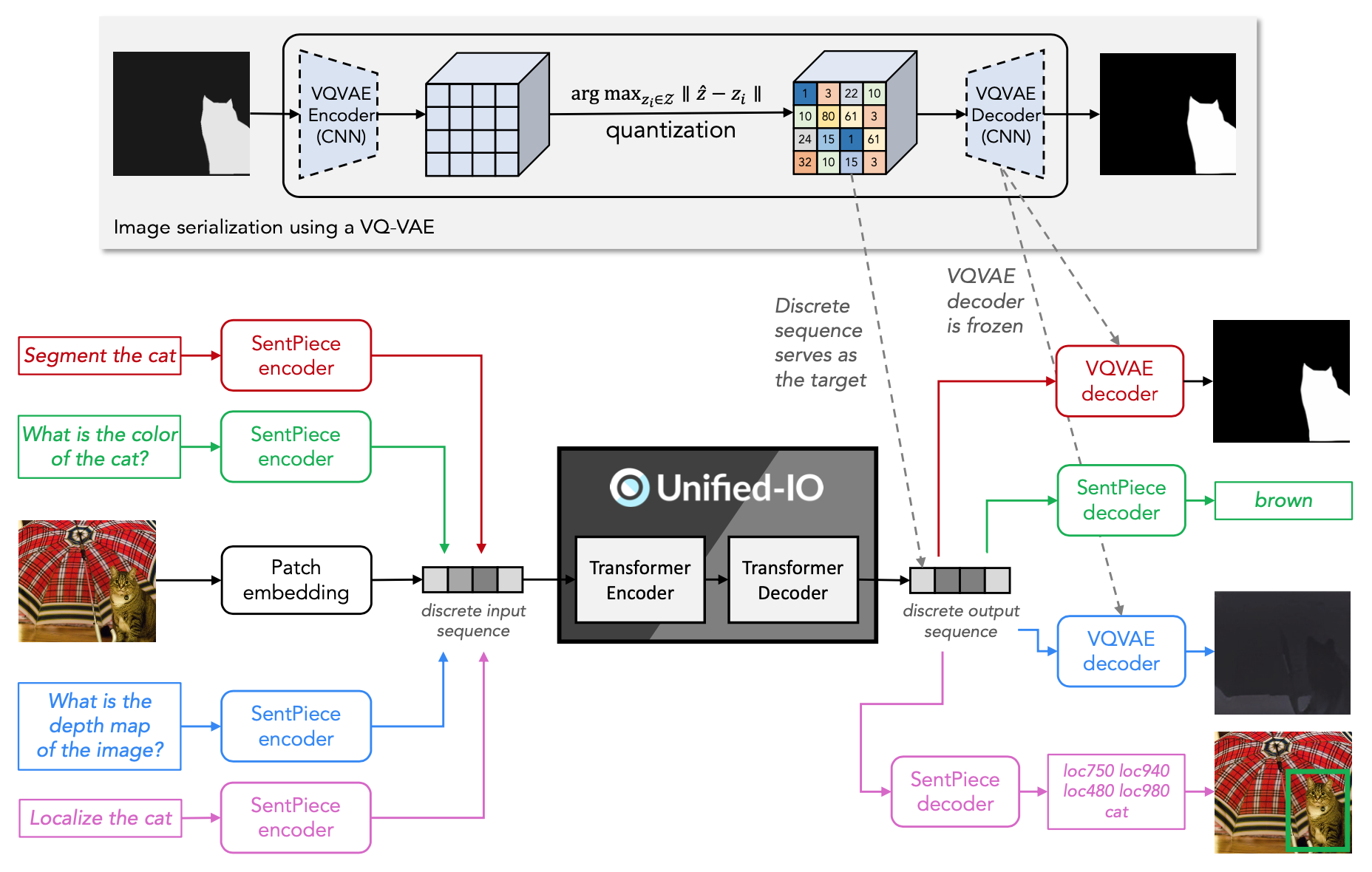
Unified-IO address it with a single input and a single output learnable heads. Text, images and other structured inputs are tokenized with a common vocabulary. Text is converted with SentencePiece, RGB images are mapped to a 8-bit color space, then encoded by a pre-trained Discrete Variational AutoEncoder (D-VAE). The authors used the encoder from VQ-GAN during training to use a target sequence of tokens. During inference, the VQ-GAN decoder converts the tokens generated by the model into the output image.
UNIFIED-IO is an encoder-decoder architecture where both the encoder and decoder are stacked transformer layers. It is trained in two stages: 1) A pre-training on unsupervised losses from text, images and image-text pairs; 2) A multi-task stage where the model is jointly trained on all tasks.
Unified-IO shows competitive results on many tasks, when compared with other specialized models. It proves that this simple common data stream allows to build a multitask model. But it comes at a price, here Unified-IO required a bigger number of parameters to be competitive. The biggest version reaches 2.8 billion parameters, and is compared to models between 50M and 470M parameters.
Controlling text-to-image models
Aside from the result’s quality on which researchers are spending lots of efforts to improve, there is one thing that in my opinion should be mentioned about and should be a topic of research: the evaluation of the generated results, specifically the text-image alignment.
$y$ must match the caption $\mathbf{c}$, in the sens that it corresponds to what $\mathbf{c}$ means. Though, there is no exact way to quantify this alignment. We all have a different perception of what composes our world. Moreover we all have different tastes and sensibilities.
The text-image alignment
Images generated with Dall-E 2 on the caption ‘A dog playing music in an opera house’.
When we generate an image conditioned on the caption “A dog playing music in an opera house.”, there is actually a very wide range of images that could match it. We did not specified what kind of dog it is, neither the architectural style of the opera, or even the style of the generated image (photography, oil painting, pixel-art …). Most people will link “Opera house” to the The Sydney Opera House or classical buildings like the Palais Garnier, which are very different. In the generated images above, the dog is not even on the stage. It is in the opera still, but you would have probably expect it to be on the stage (I would).
Text-to-image models tend to work best with more descriptive and explicit captions.
Images generated with Dall-E 2 on the caption ‘A Labrador playing piano on the stage of a modern opera house, photorealistic’.
Higher details means that the model will have to steer the image towards a more restricted area of possibilities. If you have a specific output in mind, be explicit in your prompts, the model cannot guess what’s in your mind.
Now even with high level of details, some results might be deceiving. You can notice on the images above that the dog is actually sitting and not playing. In our mind we can picture a dog actually pressing the keys with his paws, but strong models like Dall-E 2 seem to struggles. It was probably not trained with images of dog musicians.
Images generated with Dall-E 2 on the caption ‘A chimpanzee playing piano on the stage of a modern opera house, photorealistic’.
Here the musician is actually playing. We cannot tell if Dall-E has already seen monkeys playing music, but it seems to picture it quiet right. It was probably trained on pictures of monkeys doing actions with their hands.
These models make assumptions based on the data distribution they are trained with, hence they seem to have difficulties to synthesize new or unknown concepts.
Images generated with Dall-E 2 on the caption ‘A Labrador pressing piano keys with his paws, on the stage of a modern opera house, photorealistic’.
Hopefully, with a sufficient level of details we can still achieve to generate the content we expect. For the last touch, we will try with other adjectives. Adjectives can largely influence the style of the image.
Images generated with Dall-E 2 on the caption ‘A Labrador pressing piano keys with his paws, on the stage of a modern opera house, 4k, sigma 50mm’.
Here you see that 4k, Sigma 50mm completely changes the image. The image is sharper when focusing on the dog, and blur in the background. All of this with an angle close to what we expect of a 50mm lens. But we cannot really see the details of the opera, its stage and background.
Images generated with Dall-E 2 on the caption ‘A Labrador pressing piano keys with his paws, on the stage of a modern opera house, 4k, sigma 50mm’.
That’s better, we have almost everything we want here!
Prompt market
Controlling these models can be tricky, especially for beginners but even advanced users. When you have an image in mind, it is not always easy to translate it into a prompts, it often takes a few tries before having a satisfying result.
Hence it did not take much time for people to create “prompt markets”, which let you buy collections of prompts and images. PromptBase launched in June, and can give you specific keywords and sentences in order to generate results according to your needs, saving you credits, time and sometimes giving you inspiration. Prompt collections are tied to (meaning tested with) a model (Dall-E, Stable Diffusion …), but they can also be used for others of course. And if you are a talented “prompt engineer”, you can sell your own prompts!
Text-to-audio/video models
We exclusively talked about text-to-image models so far. You doubt that such advances would in no time be applied with other modalities.
Text is a very convenient interface to control these models, and the link between it and images can easily be adapted to video or audio.
Text-to-audio
AudioGen is among the first attempts of large scale text-to-audio models. It is autoregressive and based on a discrete audio representation from the raw-waveform. The audio-representation model is an auto-encoder, made of 1D-convolutional layers, trained with both an audio-level reconstruction loss and a frequency-level loss. The audio language model is a Transformer decoder, used jointly with the previous encoder and decoder, which maps text input into embeddings and uses cross-attention between them and audio embeddings. The text encoder is pre-trained T5.
Classifier-free guidance is applied on top of all. This is to my knowledge the first attempt to apply it with autoregressive models.
The authors used 10 different annotated audio datasets, and data augmentation technique consisting in fusing similar text-audio pairs, to help the model to generate new and unseen concepts.
Text-to-video
ATOW, several attempts of text-to-video have been made. Among them are CogVideo (adapted from CogView2), GODIVA, NÜWA (adapted from GODIVA), and recently Make-A-Video
Make-A-Video
Make-A-Video is actually quite simple, and very effective. Is relies on a pre-trained text-to-image model, extended with a spatiotemporal super-resolution layers, and a frame interpolation network.
Overview of the architecture of Make-A-Video. Figure taken from the original paper.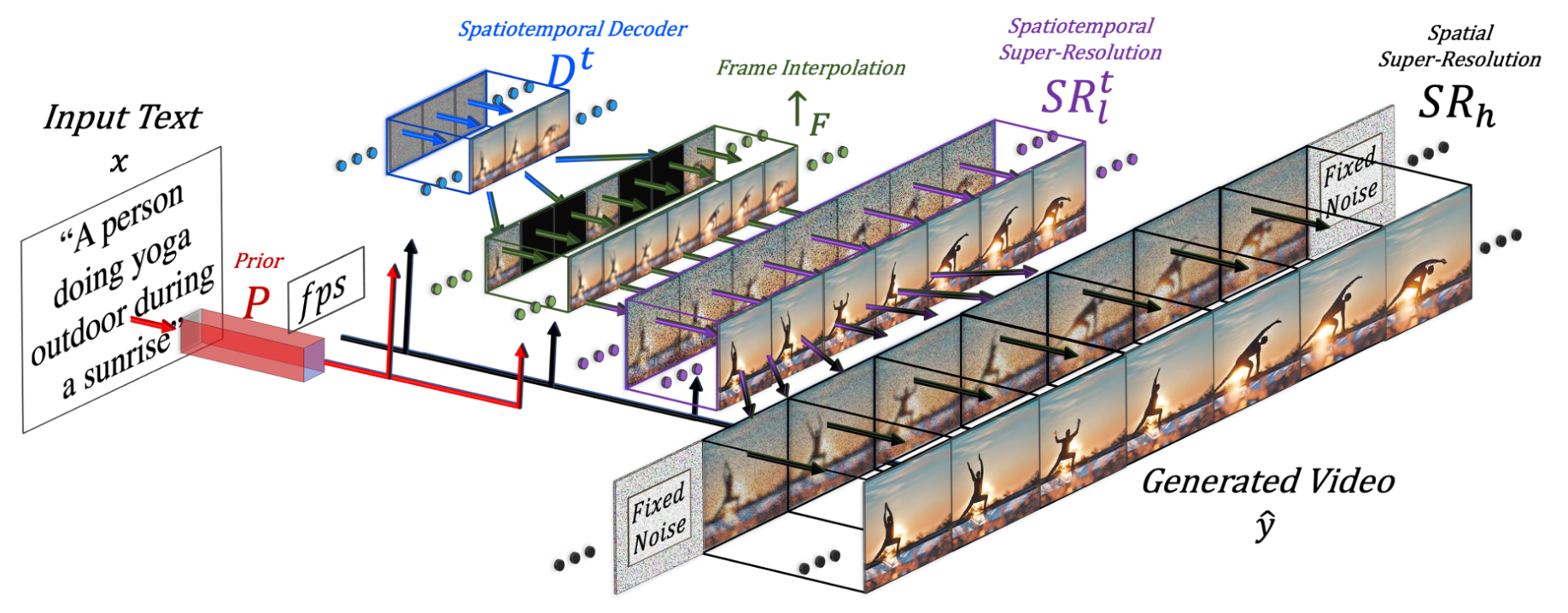
The spatiotemporal layers are made of convolutional, attention and fully connected modules. Their role is to upscale the images while maintaining their coherence among each other. The frame-interpolation networks increases the number of frames by creating intermediate frames.
Imagen Video
More recently again, researchers from Google extended Imagen (previously introduced) to generate videos: Imagen Video. Imagen Video, is a cascade of video diffusion models and a sequence of interleaved spatial and temporal video super-resolution models. The video diffusion modules are 3D U-Nets, factorized over space and time to handle several frames (the time dimension). The spacial attention blocks still operate on the space dimension, and are followed by a new time attention block operating on the frames dimension.
Schema of the 3D U-Net modules, taken from the original paper. Each block is a 4-dimension tensor: frames × height × width × channels.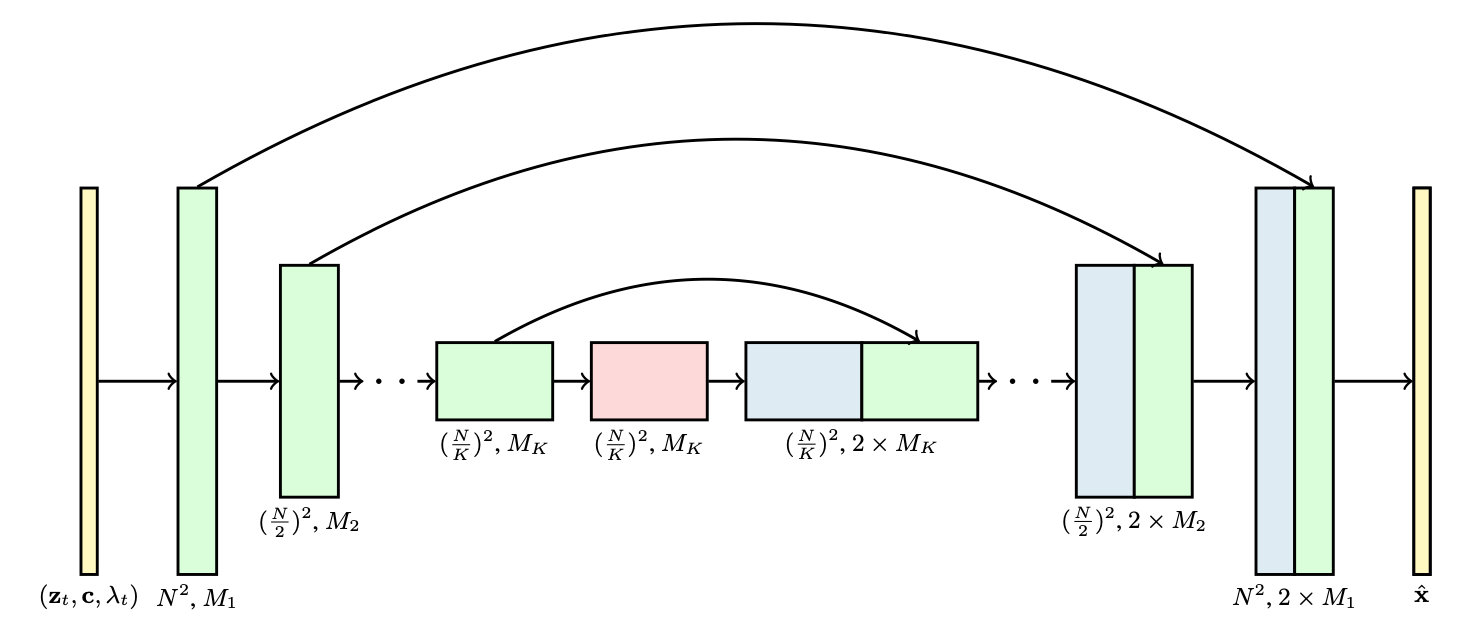
Factorized space-time attention has been shown to be effective for video modality. Imagen Video finally applies progressive distillation and classifier-free guidance to steer the results towards fidel and high quality results.
It is interesting to not that the authors found that their base video model strongly benefits from scaling the its number of parameters. This contrasts with other research findings where text-to-image models showed limited benefits in results quality when scaled. The authors hypothesized that as text-to-video is a complex task where the time dimension has to be handled, the performances of current models are saturated by their sizes, thus they benefit from scaling.
Phenaki
At the same moment of the release of Imagen Video, another team of Google (Brain) released Phenaki. Things are moving very fast.
Contrarily to Imagen Video, which is based on convolutional operations, Phenaki is sequence-based (uses discrete representations) and is built from Transformer layers. It uses a bi-directional Transformer for the generation, the “C-ViViT” architecture to train it, and a “chunked” sampling strategy during inference.
Schema of the architecture of Phenaki. Figure taken from the original paper.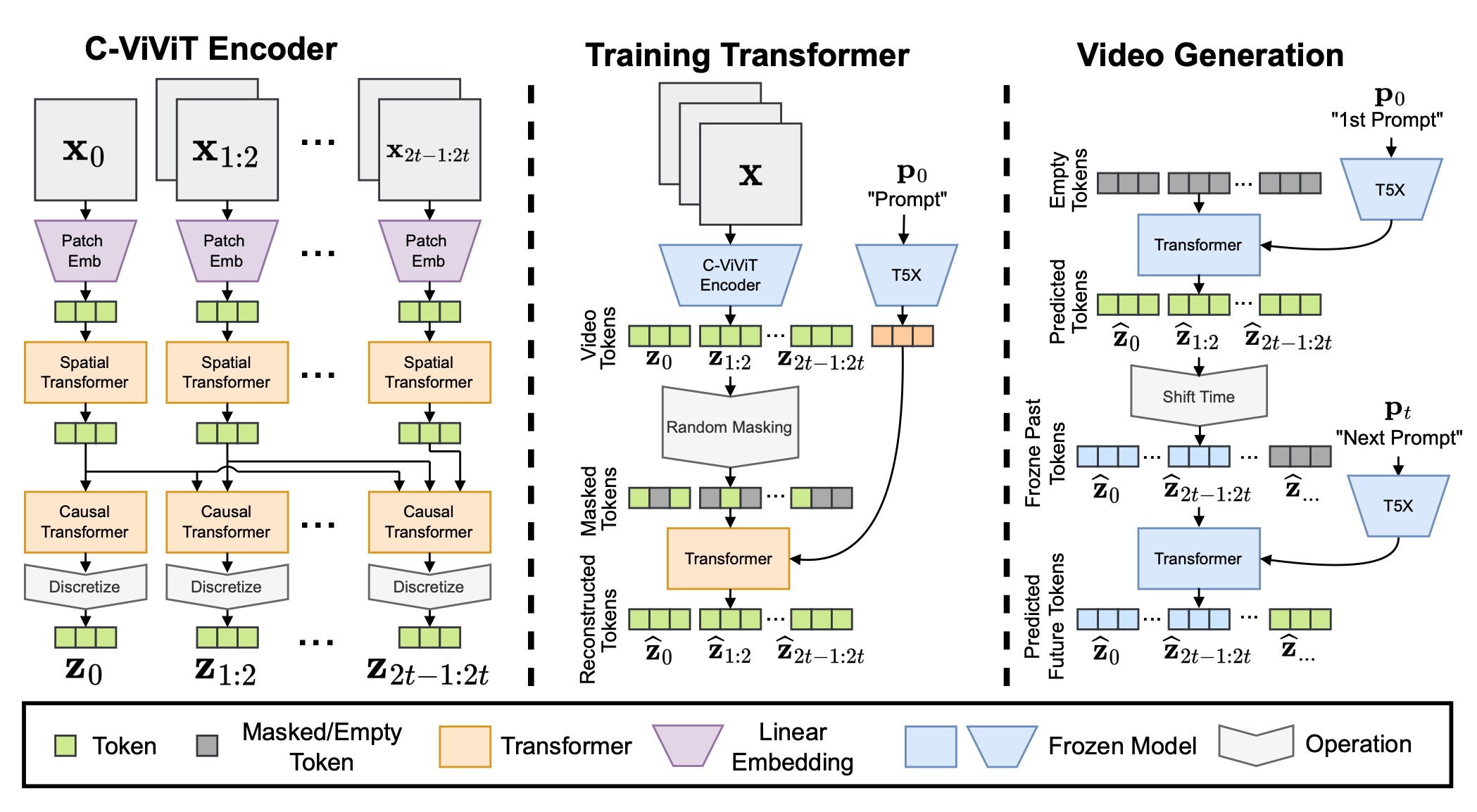
C-Vivit is a causal version of Vivit: an encoder-decoder vision-Transformer architecture. It’s goal is to create video tokens $\mathbf{z}$. These tokens are used to train the main generative Transformer, with a classic training objective while receiving the text captions (processed with a frozen T5X text encoder). During inference, chunks of video tokens are predicted to reduce the sampling time, as it can grow with long sequences and become intractable. Classifier-free guidance is used to guide the results towards good text-video alignment scores. The generated video tokens are then de-tokenized to create the actual video.
This “semi-autoregressive” process has the benefit to handle videos variable length, and can thus generate clips of durations impossible with current models in the continuous domain. The authors made a blog post with very cool generated examples that I invite you to check, on which they show two generated videos of more than 2 minutes.
Example of video generated from Phenaki, with the caption An astronaut riding a dinosaur in the park at sunrise.
Another benefit is that as the chunks of video tokens are generated, one can use different text captions and guide the generation with a detailed control.
Conclusion
In almost a few months, the “AI art” landscape has been completely shaken. The release of so much and so powerful models, in production, made people able to generate and flood the internet with unimaginable generated images.
I am particularly curious to see where the research on this topic will go from now. We have seen the power of diffusion models, but also that autoregressive ones likes PARTI can also be employed and produce amazing results. It is too bad the Google did not made it, and Imagen, available, at least in close beta, for the general public. We could have make more comprehensive comparisons.
I think the biggest steps to take now have to be toward the optimization of these models. We have seen that smart optimizations, like the one used in Stable Diffusion, allowed users to run these very large models on consumer-grade GPUs. Both attention mechanism and multiple diffusion steps are heavy operations, and getting good images require a very big computational capability that few structures have. We must also note that the community seems eager to have such models released in open-source.
References
[1] T. Karras, S. Laine, and T. Aila, “A Style-Based Generator Architecture for Generative Adversarial Networks” Jun. 2019.
[2] E. Mansimov, E. Parisotto, J. Ba, and R. Salakhutdinov, “Generating Images from Captions with Attention” 2016.
[3] K. Gregor, I. Danihelka, A. Graves, D. Rezende, and D. Wierstra, “DRAW: A Recurrent Neural Network For Image Generation” in Proceedings of the 32nd International Conference on Machine Learning, Jul. 2015, vol. 37, pp. 1462–1471.
[4] T.-Y. Lin et al., “Microsoft COCO: Common Objects in Context”, 2014.
[5] S. Reed, Z. Akata, X. Yan, L. Logeswaran, B. Schiele, and H. Lee, “Generative Adversarial Text to Image Synthesis” in Proceedings of The 33rd International Conference on Machine Learning, Jun. 2016, vol. 48, pp. 1060–1069.
[6] T. Xu et al., “AttnGAN: Fine-Grained Text to Image Generation With Attentional Generative Adversarial Networks” in CVPR, Jun. 2018.
[7] A. Ramesh et al., “Zero-Shot Text-to-Image Generation”, 2021.
[8]M. Ding et al., “CogView: Mastering Text-to-Image Generation via Transformers” in Advances in Neural Information Processing Systems, 2021, vol. 34, pp. 19822–19835.
[9] A. van den Oord, O. Vinyals, and koray kavukcuoglu, “Neural Discrete Representation Learning” in Advances in Neural Information Processing Systems, 2017, vol. 30.
[10] M. Ding, W. Zheng, W. Hong, and J. Tang, “CogView2: Faster and Better Text-to-Image Generation via Hierarchical Transformers”, arXiv, 2022.
[11] A. Radford et al., “Learning Transferable Visual Models From Natural Language Supervision”. arXiv, 2021.
[12] P. Esser, R. Rombach, and B. Ommer, “Taming Transformers for High-Resolution Image Synthesis” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2021, pp. 12873–12883.
[13] A. Brock, J. Donahue, and K. Simonyan, “Large Scale GAN Training for High Fidelity Natural Image Synthesis” 2019.
[14] O. Patashnik, Z. Wu, E. Shechtman, D. Cohen-Or, and D. Lischinski, “StyleCLIP: Text-Driven Manipulation of StyleGAN Imagery” in Proceedings of the IEEE/CVF International Conference on Computer Vision (ICCV), Oct. 2021, pp. 2085–2094.
[15] A. Nichol et al., “GLIDE: Towards Photorealistic Image Generation and Editing with Text-Guided Diffusion Models”, arXiv, 2021.
[16] J. Ho and T. Salimans, “Classifier-Free Diffusion Guidance”, NeurIPS 2021 Workshop on Deep Generative Models and Downstream Applications, 2021.
[17] A. Ramesh, P. Dhariwal, A. Nichol, C. Chu, and M. Chen, “Hierarchical Text-Conditional Image Generation with CLIP Latents”, arXiv, 2022.
[18] C. Saharia et al., “Photorealistic Text-to-Image Diffusion Models with Deep Language Understanding”, arXiv, 2022.
[19] J. Ho, C. Saharia, W. Chan, D. J. Fleet, M. Norouzi, and T. Salimans, “Cascaded Diffusion Models for High Fidelity Image Generation” Journal of Machine Learning Research, vol. 23, no. 47, pp. 1–33, 2022.
[20] A. Q. Nichol and P. Dhariwal, “Improved Denoising Diffusion Probabilistic Models” in Proceedings of the 38th International Conference on Machine Learning, Jul. 2021, vol. 139, pp. 8162–8171.
[21] J. Yu et al., “Scaling Autoregressive Models for Content-Rich Text-to-Image Generation”, arXiv, 2022.
[22] R. Rombach, A. Blattmann, D. Lorenz, P. Esser, and B. Ommer, “High-Resolution Image Synthesis With Latent Diffusion Models” in Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Jun. 2022, pp. 10684–10695.
[23] J. Lu, C. Clark, R. Zellers, R. Mottaghi, and A. Kembhavi, “Unified-IO: A Unified Model for Vision, Language, and Multi-Modal Tasks”, arXiv, 2022.
[24] U. Singer et al., “Make-A-Video: Text-to-Video Generation without Text-Video Data.” arXiv, 2022.
[25] Anonymous, “AudioGen: Textually Guided Audio Generation” 2023.
[26] J. Ho et al., Imagen Video: High Definition Video Generation with Diffusion Models, arXiv, 2022. doi: 10.48550/ARXIV.2210.02303.
[28] J. Ho, T. Salimans, A. Gritsenko, W. Chan, M. Norouzi, and D. J. Fleet, Video Diffusion Models. arXiv, 2022. doi: 10.48550/ARXIV.2204.03458.
[29] R. Villegas et al., Phenaki: Variable Length Video Generation From Open Domain Textual Description, submitted for ICLR 2023.